Apache Spark >> Schema
Table of Contents
In this article, we will talk about the schema of Spark DataFrame.
A Spark schema is a definition of column names and types.
In Spark, the schema can also be inferred when reading the data.
![[Apache Spark Schema] Introduction](/img/apache-spark_schemas.png)
Prepare data
We need to prepare some sample data first for demonstration.
Download the CSV file below
The detailed data structure is as follows.
| column | summary |
|---|---|
| id | student’s ID |
| first_name | student’s first name |
| last_name | student’s last name |
| birth | student’s birthday |
| gender | student’s gender |
| class | student’s class |
| subject | the subjects that students are learning |
| score | student’s scores of subjects |
Next, let’s start our local Spark development environment and upload the sample CSV file to the data folder.
For more information about how to create a local Spark development and upload files, you can read the article below.
Apache Spark » Create a Local Apache Spark Development Environment on Windows With Just Two Commands https://thats-it-code.com/apachespark/apachespark__create-a-local-apache-spark-development-environment-with-just-two-commands/
Show schema of DataFrame
Firstly, let’s create a Spark session.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("MyApp") \
.getOrCreate()
And let’s read our sample CSV file (student_scores.csv).
We need to specify that there is a header option.
df = spark.read.option("header", True).csv("data/student_scores.csv")
Next, let’s show some rows.
df.show()
Only the top 20 rows are shown by default.
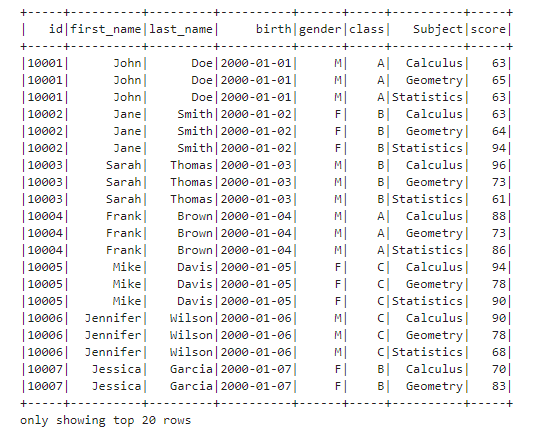
Next, let’s show the schema inferred by default.
df.printSchema()

As you can see, all the columns in the CSV data are inferred as string type.
Define the schema of data
We can define the schema of the data.
from pyspark.sql.types import StructField, StructType, StringType, IntegerType, DateType
schema = StructType([
StructField("id", StringType(), False),
StructField("first_name", StringType(), False),
StructField("last_name", StringType(), False),
StructField("birth", DateType(), True),
StructField("gender", StringType(), True),
StructField("class", StringType(), True),
StructField("Subject", StringType(), True),
StructField("score", IntegerType(), True)
])
And specify the schema when reading the data.
df2 = spark.read.option("header", True).format('csv').load('data/student_scores.csv',schema=schema, inferSchema=False)
df2.show()
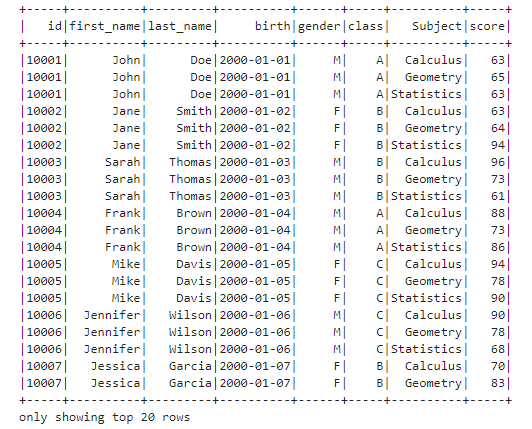
Let’s check the schema again.
df2.printSchema()

Load schema from json file
It’s not flexible to define the schema in the code.
We can define the schema in a JSON file, then load it and convert it to the schema.
We can define the above schema like this.
{
"type" : "struct",
"fields" : [ {
"name" : "id",
"type" : "string",
"nullable" : false,
"metadata": {}
}, {
"name" : "first_name",
"type" : "string",
"nullable" : false,
"metadata": {}
}, {
"name" : "last_name",
"type" : "string",
"nullable" : false,
"metadata": {}
}, {
"name" : "birth",
"type" : "date",
"nullable" : true,
"metadata": {}
}, {
"name" : "gender",
"type" : "string",
"nullable" : true,
"metadata": {}
}, {
"name" : "class",
"type" : "string",
"nullable" : true,
"metadata": {}
}, {
"name" : "Subject",
"type" : "string",
"nullable" : true,
"metadata": {}
}, {
"name" : "score",
"type" : "integer",
"nullable" : true,
"metadata": {}
} ]
}
You can copy the above definition and save it as schema.json file.
And upload it to the root folder of Jupyter notebook workspace.
Firstly, we need to read the schema JSON file.
import json
with open('schema.json', 'r') as schema_json_file:
schema_json = json.load(schema_json_file)
And we can convert the JSON format definition to Spark schema using StructType.fromJson() method.
schema2 = StructType.fromJson(schema_json)
schema2

Finally, we also use the same read way as above and specify the schema.
df3 = spark.read.option("header", True).format('csv').load('data/student_scores.csv',schema=schema2, inferSchema=False)
df3.show()
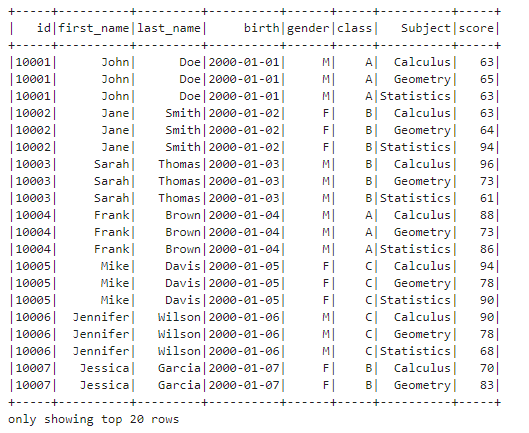
Let’s check the schema of DataFrame again.
df3.printSchema()

Conclusion
Spark can infer the data schema automatically.
We can define the schema of the data using all kinds of Type in pyspark.sql.types.
And we can also define the schema in JSON file and use it when reading data.