Pandas >> Data Combination(1): merge()
Table of Contents
In this tutorial, we will explain how to combinate/join multiple DataFrames using merge().
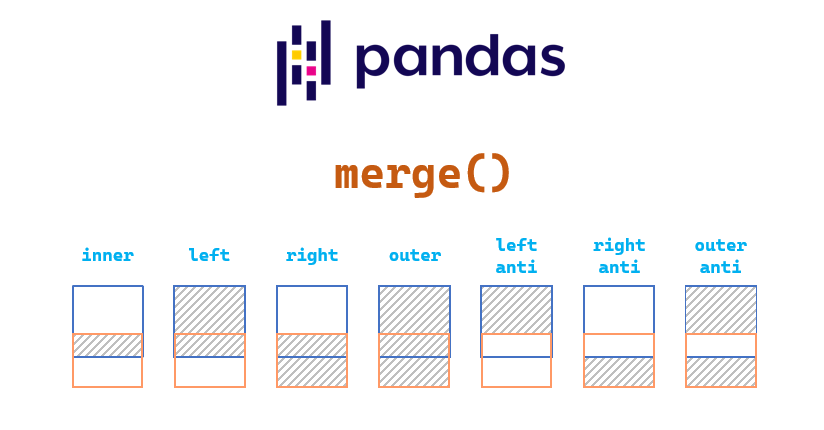
Introduction to merge()
Firstly, let’s see the definition of the merge() function.
pandas.merge: Merge DataFrame or named Series objects with a database-style join.
https://pandas.pydata.org/docs/reference/api/pandas.merge.html
pandas.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', ‘_y’), copy=True, indicator=False, validate=None)
Let’s explain the main parameters.
- left: The DataFrame on the left.
- right: The DataFrame on the right.
- how: How to join the two DataFrames. There are five SQL-like join ways. left, right, outer, inner, cross. If not specified, the default joining way is inner.
- on: Column for joining (key) if the column names from both sides are the same.
- left_on, right_on: If we want to specify the columns of two sides for joining separately, we can specify the columns from the left side using left_on, and specify the columns from the right side using right_on.
- suffixes: If there are duplicated columns after joining, we can append suffixes for the duplicated columns. By default, _x is appended to the column from the left side, and _y is appended to the column from the right side.
Data Preparation
Let’s define the data on the left.
df_scores = pd.DataFrame({
"id": ["1003", "1004", "1005", "1006", "1007"],
"fname": ["Mike", "Tom", "Mary", "Bob", "Kevin"],
"lname": ["Brown", "Davis", "Clark", "Lopez", "Wilson"],
"gender": ["M", "M", "F", "M", "M"],
"subject": ["Math", "Art", "Engilish", "Physics", "Music"],
"score": [85, 78, 88, 90, 80]
})
df_scores

Define the data on the right.
import pandas as pd
df_students = pd.DataFrame({
"id": ["1001", "1002", "1003", "1004", "1005"],
"first_name": ["John", "Sarah", "Mike", "Tom", "Mary"],
"last_name": ["Doe", "Smith", "Brown", "Davis", "Clark"],
"gender": ["M", "F", "M", "M", "F"]
})
df_students

JOIN
INNER JOIN
Let’s see the image below, the inner join will combinate the data from two sides with the same key values.

For example, we join the df_students and df_scores using the inner join.
pd.merge(df_scores, df_students, on="id")
# OR
pd.merge(df_scores, df_students, how='inner', on="id")

LEFT JOIN
The left join is similar to a SQL left outer join.
The rows from two sides with the same id will be concatenated as one row.
If the combined key (id) exists on the left and does not exist on the right. The values of the columns belonging to the right side will all be NaN.

Example code
pd.merge(df_scores, df_students, how='left', on="id")

RIGHT JOIN
The right join is similar to a SQL right outer join.
The rows from two sides with same id will be concatenated as one row.
If the combined key (id) exists on the right and does not exist on the left. The values of the columns belonging to the left side will all be NaN.

Example code
pd.merge(df_scores, df_students, how='right', on="id")

OUTER JOIN
outer join is similar to a SQL full outer join.
All the data from two sides will be kept and the values of the columns will all be NaN if id only exists on the other side.

Example code
pd.merge(df_scores, df_students, how='outer', on="id")

CROSS JOIN
Cross join will create the cartesian product from both DataFrames. In other words, it will generate all possible combinations of two DataFrames.

Example code
Prepare the DataFrame on the left side.
df_left = pd.DataFrame(["left1", "left2", "left3"], columns=["col_1"])
df_left

Prepare the DataFrame on the right side.
df_right = pd.DataFrame(["right1", "right2"], columns=["col_1"])
df_right

Let’s combinate the two DataFrames by cross join.
As you can see, all the combinations are generated. 3 x 2 = 6
pd.merge(df_left, df_right, how='cross')

LEFT EXCLUSIVE/ANTI JOIN
left exclusive join (also called left anti join) will select the data that the values of the key column only exist on the left side.

We can use the parameter indicator to distinguish which side the data exists on.
If indicator=True is specified, a _merge column will be added.
For example, we can use outer join and view all the indicator results first.
pd.merge(df_scores, df_students, how='outer', on="id", indicator=True)

We can find there are three different values.
- both: the values of the key column exist on two sides
- left_only: the values of the key column only exist on the left
- right_only: the values of the key column only exist on the right
We only need to filter out the results where the indicators are left_only in order to achieve left exclusive/anti join.
Example code
pd.merge(df_scores, df_students, how='outer', on="id", indicator=True) \
.query("_merge == 'left_only'")

We can drop the indicator column (_merge) if it is not needed.
axis=1 means we want to remove a column named _merge.
If we want to delete rows, we can use axis=0.
pd.merge(df_scores, df_students, how='outer', on="id", indicator=True) \
.query("_merge == 'left_only'") \
.drop("_merge", axis=1)

RIGHT EXCLUSIVE/ANTI JOIN
right exclusive join (also called the right anti join) will select the data that the values of the key column only exist on the right side.

Similarly, we only need to filter out the results where the indicators are right_only in order to achieve the right exclusive/anti join.
Example code
pd.merge(df_scores, df_students, how='outer', on="id", indicator=True) \
.query("_merge == 'right_only'") \
.drop("_merge", axis=1)

FULL OUTER EXCLUSIVE/ANTI JOIN
full outer exclusive join (also called the full outer anti join) will select the data that the values of the key column only exist on the left or right side. The data existing on both sides will not be included.

Similarly, we only need to filter out the results where the indicators are left_only or right_only in order to achieve full outer exclusive/anti join.
Example code
pd.merge(df_scores, df_students, how='outer', on="id", indicator=True) \
.query("_merge == 'left_only' or _merge == 'right_only'") \
.drop("_merge", axis=1)

JOIN by multiple columns
We can use multiple columns as combination keys to join the DataFrames.
If the column names on both sides are the same, we can specify a column name list for the on parameter.
If the column names on both sides are different, we can specify the column name list for combination separately.
For example, instead of using the id column, we use the first_name and last_name for data combination.
The column names are as follows.
Left(df_scores): fname, lname
Right(df_students): first_name, last_name
Attention: The order of the left and right column names must be the same.
Example code
pd.merge(df_scores, df_students, how='inner'
, left_on=["fname", "lname"]
, right_on=["first_name", "last_name"])

Removing duplicate columns
Sometimes, there will be some columns with the same name and the same values that exist on both sides.
For example, there are id_x and id_y, gender_x and gender_y in the above result.
We can remove the duplicate columns as follows.
Example code
# Get the columns that only exist on the right side
target_cols = list(df_students.columns.difference(df_scores.columns))
# Append the key columns
target_cols.append("id")
target_cols
['first_name', 'last_name', 'id']
# We only use the above columns of the DataFrame on the right side (df_students)
pd.merge(df_scores, df_students[target_cols], how='inner', on="id")
We will find there are no duplicate columns in the result.

Specify suffixes for columns with the same name
Sometimes, we need to keep the columns with the same name from both sides.
By default, _x will be added to the column on the left, and _y will be added to the column on the right.
If we want to customize the suffixes, we can use the suffixes parameter.
For example, if we want to add _left to the column on the left, and add _right to the column on the right, we can set the parameter suffixes to ["_left", “_right”].
If we don’t set any suffix on some side, we can set an empty string ('').
Example code
pd.merge(df_scores, df_students, how='inner', on="id", suffixes=["_left", "_right"])
As you can see, the columns with the same name have been set to gender_left and gender_right.

Conclusion
We can use the merge() method to implement the SQL-like joins (inner join, left join, right join, full outer join, cross join, left exclusive/anti join, right exclusive/anti join, full outer exclusive/anti join).
We can join by a single column or multiple columns.
We can remove duplicate columns when joining and specify suffixes for the columns with the same name.