Implement Retrieval-Augmented Generation (RAG) with Docker, FastAPI, OpenSearch, transformers (GPT-2) in 10 Minutes
Table of Contents
Introduction
Retrieval-Augmented Generation (RAG) is a cutting-edge method in Natural Language Processing (NLP) that combines retrieval-based techniques with large language models (LLMs). Unlike traditional models that rely solely on pre-trained knowledge, RAG enriches responses by retrieving relevant external information from a document store or knowledge base. This approach not only enhances the quality, relevance, and factual accuracy of generated content but also significantly reduces the hallucination of LLMs by grounding their responses in real, retrievable data. As a result, RAG is ideal for applications like chatbots, Q&A systems, and information retrieval, where precision and reliability are crucial.
In this tutorial, we’ll build a RAG-powered project (FastAPI) using Python, Hugging Face models, OpenSearch, and Docker.
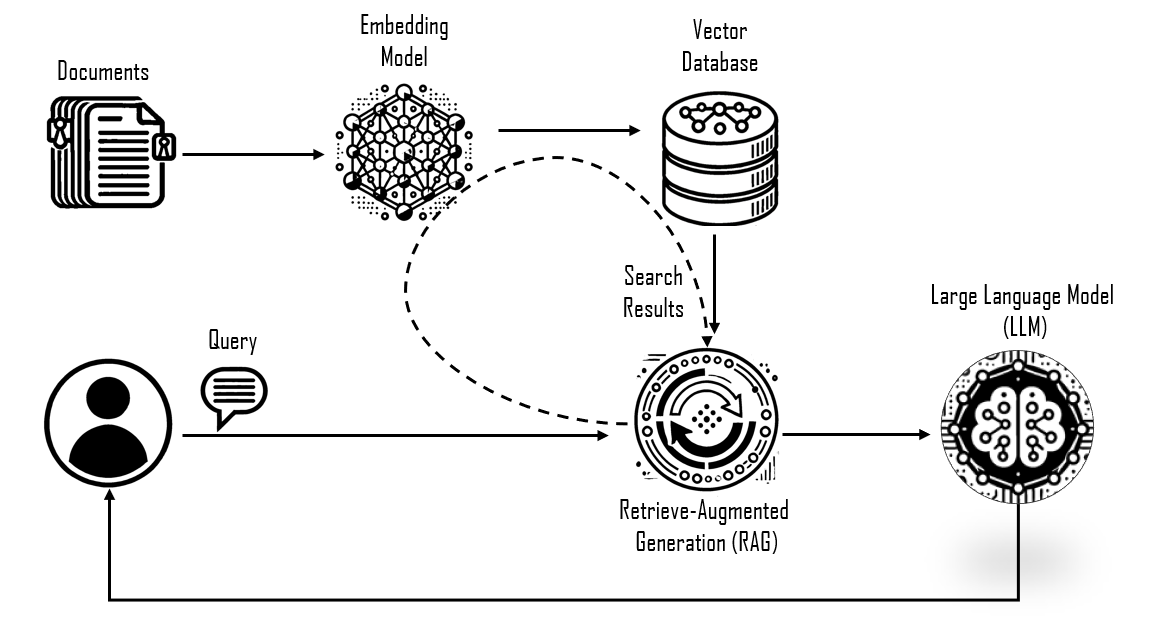
What is Retrieval-Augmented Generation (RAG)?
RAG combines retrieval-based techniques with generative models to create accurate and contextually relevant responses by retrieving external documents and combining them with the generated text. Here’s how it works:
-
Retrieve Phase: When a query is made, generally it searches a knowledge base or document store, which are typically vector databases, for relevant content. The retrieval process often uses vector search techniques (e.g., semantic search) to find documents based on their embeddings.
-
Generate Phase: After retrieving relevant documents, a generative model (such as GPT, BERT, or any other large language model) processes both the query and the retrieved content to produce a response.
Prerequisites
- Python 3.x installed on your machine.
- Docker installed for containerization.
Project Setup and Environment
We’ll walk through the steps of setting up the environment, indexing documents, building the RAG retrieval and generation system, and deploying it with Docker.
Step 1: Create the Project Directory
Create the following project structure:
rag_project/
├── app/
│ ├── main.py # FastAPI app with RAG logic
│ ├── clear_index.py # Script to clear the document index
│ ├── insert_docs.py # Script to insert documents into OpenSearch
│ ├── requirements.txt # Required Python packages
├── Dockerfile # Docker setup
├── docker-compose.yml # Docker Compose for OpenSearch and API
└── README.md # Project documentation
Step 2: Python Environment Setup
In the requirements.txt file, list the necessary dependencies:
transformers
accelerate
sentence-transformers
opensearch-py
fastapi
uvicorn
datamodel_code_generator
jsonschema
These packages include:
- transformers: Hugging Face’s library to use pre-trained transformer models.
- sentence-transformers: Used for embedding documents into vectors.
- opensearch-py: Python client for interacting with OpenSearch.
- fastapi: Framework for building APIs in Python.
- uvicorn: ASGI server for serving FastAPI apps.
- datamodel_code_generator: Tool for generating Pydantic models from schemas.
- jsonschema: Library for validating JSON data.
Setup a virtual env and install these packages by running:
python -m venv .venv
source .venv/bin/activate # On Windows, use .venv\Scripts\activate
pip install -r app/requirements.txt
Step 3: Set Up OpenSearch with Docker Compose
Create a docker-compose.yml file to set up OpenSearch, Kibana, and the main application using Docker Compose. Docker Compose allows you to define and run multi-container Docker applications. Here, we set up OpenSearch (to store and retrieve documents), Kibana (for OpenSearch visualization), and the FastAPI application:
version: '3.7'
services:
opensearch:
image: opensearchproject/opensearch:1.2.3
container_name: opensearch
environment:
- discovery.type=single-node
- plugins.security.disabled=true
ports:
- 9200:9200
- 9600:9600
volumes:
- opensearch-data:/usr/share/opensearch/data
kibana:
image: opensearchproject/opensearch-dashboards:1.2.0
container_name: opensearch-dashboards
ports:
- 5601:5601
environment:
OPENSEARCH_HOSTS: '["http://opensearch:9200"]'
depends_on:
- opensearch
app:
build: .
container_name: rag-app
ports:
- 8000:8000
depends_on:
- opensearch
volumes:
- ./app:/app
volumes:
opensearch-data:
This configuration sets up OpenSearch and Kibana services on their respective ports. It also connects the FastAPI application to OpenSearch.
Step 4: Indexing Documents into OpenSearch
In insert_docs.py, you use a pre-trained sentence transformer model to convert documents into embeddings and store them in OpenSearch:
from sentence_transformers import SentenceTransformer
from opensearchpy import OpenSearch
# Load a pre-trained sentence transformer model for embeddings
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')
# List of 30 documents split into 6 different topics
documents = [
# Topic 1: Machine Learning
{"id": "1", "text": "Machine learning is the study of computer algorithms that improve automatically through experience."},
{"id": "2", "text": "Supervised learning is a type of machine learning where the model is trained on labeled data."},
{"id": "3", "text": "Unsupervised learning is used to find patterns in data without explicit labels."},
{"id": "4", "text": "Deep learning is a subset of machine learning that uses neural networks with many layers."},
{"id": "5", "text": "Reinforcement learning is an area of machine learning concerned with how agents ought to take actions to maximize cumulative reward."},
# Topic 2: Programming Languages
{"id": "6", "text": "Python is a popular programming language known for its simplicity and versatility."},
{"id": "7", "text": "JavaScript is the programming language of the web, used for building interactive websites."},
{"id": "8", "text": "Java is a general-purpose programming language that is designed to have as few implementation dependencies as possible."},
{"id": "9", "text": "C++ is a powerful programming language that extends the C programming language with object-oriented features."},
{"id": "10", "text": "Rust is a systems programming language focused on safety, performance, and concurrency."},
# Topic 3: Cloud Computing
{"id": "11", "text": "Cloud computing is the delivery of computing services over the internet to offer faster innovation, flexible resources, and economies of scale."},
{"id": "12", "text": "Infrastructure as a Service (IaaS) is a form of cloud computing that provides virtualized computing resources over the internet."},
{"id": "13", "text": "Platform as a Service (PaaS) is a category of cloud computing services that provides a platform allowing customers to develop, run, and manage applications."},
{"id": "14", "text": "Software as a Service (SaaS) allows users to connect to and use cloud-based apps over the internet."},
{"id": "15", "text": "Serverless computing allows developers to build and run applications without having to manage infrastructure."},
# Topic 4: Cybersecurity
{"id": "16", "text": "Cybersecurity involves protecting systems, networks, and programs from digital attacks."},
{"id": "17", "text": "Phishing is a type of cyberattack that uses disguised email as a weapon to steal sensitive data."},
{"id": "18", "text": "Encryption is the process of encoding information to prevent unauthorized access."},
{"id": "19", "text": "A firewall is a network security system that monitors and controls incoming and outgoing network traffic."},
{"id": "20", "text": "Multi-factor authentication (MFA) adds an additional layer of security by requiring two or more verification factors to access a resource."}
]
# Convert documents to embeddings
document_embeddings = model.encode([doc['text'] for doc in documents])
# Connect to OpenSearch
client = OpenSearch(
hosts=[{'host': 'localhost', 'port': 9200}],
http_auth=('admin', 'admin')
)
# Indexing documents in OpenSearch
for idx, doc in enumerate(documents):
client.index(index="rag-documents", id=doc["id"], body={"text": doc["text"], "embedding": document_embeddings[idx].tolist()})
print("Documents have been successfully indexed.")
Here, documents are split into topics (like Machine Learning and Programming Languages). These documents are converted into embeddings (numerical vectors) using a pre-trained sentence transformer model and then stored in OpenSearch.
To index the documents, run:
python app/insert_docs.py
Step 5: Clear Document Index
To clear the indexed documents from OpenSearch, use clear_index.py:
from opensearchpy import OpenSearch
# Connect to OpenSearch
client = OpenSearch(
hosts=[{'host': 'localhost', 'port': 9200}],
)
# Specify the index you want to clear
index_name = "rag-documents"
# Delete all documents in the index using the match_all query
response = client.delete_by_query(
index=index_name,
body={
"query": {
"match_all": {} # This will delete all documents
}
}
)
# Print the response to verify the deletion
print(f"Deleted {response['deleted']} documents from index {index_name}.")
Run the script:
python app/clear_index.py
Step 6: Build the FastAPI RAG Logic
In main.py, implement the FastAPI service to retrieve documents from OpenSearch and generate responses using Hugging Face models:
from pydantic import BaseModel
from fastapi import FastAPI
from transformers import pipeline
from opensearchpy import OpenSearch
app = FastAPI()
# Define the input model for the API
class Query(BaseModel):
query: str
# Connect to OpenSearch
client = OpenSearch(
hosts=[{'host': 'opensearch', 'port': 9200}],
)
# Load the generative model
generator = pipeline('text-generation', model='openai-community/gpt2')
@app.post("/rag/")
async def rag(query: Query):
# Retrieve documents from OpenSearch
retrieved_docs = client.search(index="rag-documents", body={
"query": {
"match": {
"text": {
"query": query.query,
"fuzziness": "AUTO",
"minimum_should_match": "85%"
}
}
}
})
retrieved_texts = [doc['_source']['text'] for doc in retrieved_docs['hits']['hits']]
# Generate a response using the generative model
context = " ".join(retrieved_texts)
generated = generator(f"{query.query} {context}", max_length=300, num_return_sequences=1)
return {"response": generated[0]['generated_text']}
This FastAPI service allows users to submit a query, retrieve related documents from OpenSearch, and generate a response using the GPT-2 model from Hugging Face.
Step 7: Create the Dockerfile
Create a Dockerfile to containerize the FastAPI app:
# Use the official Python image
FROM python:3.9
# Set the working directory
WORKDIR /app
# Install dependencies
COPY ./app/requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir -r /app/requirements.txt
# Copy the application code
COPY ./app /app
# Expose the app's port
EXPOSE 8000
# Run the FastAPI app with Uvicorn
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
Step 8: Test the RAG API
Start OpenSearch, Kibana and RAG applicaton (FastAPI) using Docker Compose:
docker-compose up -d
If you want to stop all the services, just run this command.
docker-compose down
After starting all the services (It may take a while for completing the service start because initializing the model will take some time), test the RAG API by making a POST request to the /rag/ endpoint:
You can run this command in a separate terminal.
docker logs rag-app
When you see this logs, it means the RAG application is ready.
INFO: Started server process [7]
INFO: Waiting for application startup.
INFO: Application startup complete.
Then run this command to test the RAG API.
curl -X POST "http://localhost:8000/rag/" -H "Content-Type: application/json" -d '{"query": "What is machine learning?"}'
You will see the result similar with the following one.
{"response":"What is machine learning? Deep learning is a subset of machine learning that uses neural networks with many layers. Machine learning is the study of computer algorithms that improve automatically through experience. Supervised learning is a type of machine learning where the model is trained on labeled data. Reinforcement learning is an area of machine learning concerned with how agents ought to take actions to maximize cumulative reward. Learning is an important concept among the computer science fields of data science. Machine learning in particular has traditionally focused on understanding the nature of action patterns in decision making. It has also found it useful to understand how the human brain integrates machine learning through action-related memory. More than any other type of data, machine learning has come in to be a useful way to solve this problem. A model was given an answer, it was a search for a pattern and the search returned it. However, these explanations are not adequate to describe how the search might improve the model. Learning can sometimes even reduce the time required for training an algorithm from the original analysis. For this reason, computer science has become a crucial part of what we do when it comes to data science, especially when the study is about generalizing an algorithm from generalizations. To answer these questions, there is a number of problems in machine learning that are often neglected in the current field. A few are the following and some of them are in order: What is Machine Learning? A fundamental problem in artificial intelligence is training a model using a set of algorithms. Since all"}
Conclusion
This article provided a step-by-step guide to building a RAG-powered system using Python, Hugging Face models, and OpenSearch. You learned how to index documents, set up a FastAPI service, and deploy the application using Docker. This setup can be easily scaled to handle more complex use cases for NLP applications.